核心原理
无论哪种方法,核心思路都是一样的:

(图片来源网络,侵删)
- 获取图集内容字段(通常是
body或litpic)。 - 将该字段中的所有图片地址提取出来,存入一个数组。
- 从数组中索引为
1的元素(因为数组索引从0开始,所以第二张图片的索引是1)获取图片地址。
页(文章页)调用图集的第二张图
这是最常见的需求,比如在文章详情页,除了显示封面图,还想额外显示一张图片作为预览或副图。
使用场景: 在 article_article.htm 模板文件中。
代码示例:
在模板的适当位置,插入以下代码:
(图片来源网络,侵删)
{dede:field.body runphp='yes'}
// 1. 获取图集内容
$body = @me;
// 2. 使用正则表达式提取所有图片地址
// preg_match_all 的 '/<img.*?src=['"]?(.*?)['"].*?>/i' 是一个常用的匹配img标签src属性的正则
preg_match_all('/<img.*?src=['"]?(.*?)['"].*?>/i', $body, $matches);
// 3. 判断是否找到了图片,并且数量大于1
if (isset($matches[1]) && is_array($matches[1]) && count($matches[1]) > 1) {
// 4. 获取第二张图片的地址 (索引为1)
$second_img_url = $matches[1][1];
// 5. 输出第二张图片
@me = "<img src='{$second_img_url}' alt='第二张图片' />";
} else {
// 如果图片不足一张,可以输出默认图片或者留空
@me = "<img src='/images/default.jpg' alt='默认图片' />";
}
{/dede:field.body}
代码解释:
{dede:field.body runphp='yes'}: 这是织梦调用字段并执行PHP代码的标准写法。@me代表当前字段的值,在这里就是文章的bodypreg_match_all(...): 这是一个强大的PHP函数,用于在字符串中查找所有匹配正则表达式的模式。$matches[1]:preg_match_all会将匹配结果存入$matches数组。$matches[0]存放的是完整的匹配字符串(即整个<img>标签),而$matches[1]存放的是第一个子表达式(即src的值)。count($matches[1]) > 1: 这是一个判断,确保图集中至少有两张图片,避免数组越界错误。@me = "...": 将处理好的结果(即第二张图片的HTML代码)赋值给@me,模板引擎会将其输出。
在列表页(首页、栏目页等)调用图集的第二张图
在列表页循环调用文章时,如果某篇文章是图集,你想在摘要旁边显示它的第二张图。
使用场景: 在 index.htm, list_article.htm 等模板文件中,通常在 {dede:list} 或 {dede:arclist} 标签循环体内使用。
代码示例:
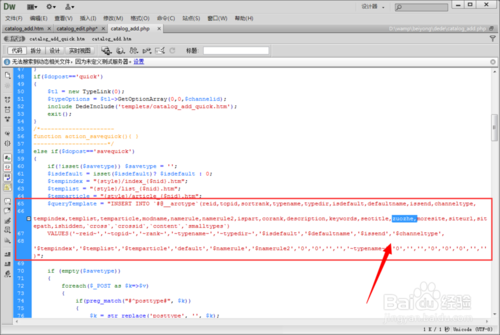
(图片来源网络,侵删)
在 {dede:list} 循环中,使用以下代码:
{dede:list pagesize='10'}
<li>
<!-- 调用第二张图片 -->
{dede:field.body runphp='yes'}
$body = @me;
preg_match_all('/<img.*?src=['"]?(.*?)['"].*?>/i', $body, $matches);
if (isset($matches[1]) && is_array($matches[1]) && count($matches[1]) > 1) {
$second_img_url = $matches[1][1];
@me = "<img src='{$second_img_url}' width='100' height='100' />";
} else {
@me = "<img src='/images/default.jpg' width='100' height='100' />";
}
{/dede:field.body}
<a href="[field:arcurl/]">[field:title/]</a>
</li>
{/dede:list}
代码解释:页的原理完全一样,只是应用在了列表页的循环标签中,每次循环都会对当前文章的 body 字段进行处理,提取出第二张图片。
通过自定义函数(更推荐,代码更简洁)
如果需要在多个地方重复使用这个功能,最好的方式是将其封装成一个自定义函数,然后在模板中直接调用。
步骤 1:创建函数文件
在 include/extend.func.php 文件中(如果不存在则创建)添加以下函数:
/**中的第二张图片地址
* @param string $body 文章内容
* @param string $default 默认图片地址
* @return string 图片地址
*/
function GetSecondImg($body, $default = '')
{
if (empty($body)) {
return $default;
}
preg_match_all('/<img.*?src=['"]?(.*?)['"].*?>/i', $body, $matches);
if (isset($matches[1]) && is_array($matches[1]) && count($matches[1]) > 1) {
return $matches[1][1];
}
return $default;
}
步骤 2:在模板中调用函数
你可以在任何模板文件中通过 {dede:函数名} 的方式来调用。
页 (article_article.htm):**
<img src="{dede:GetSecondImg(@me, '/images/default.jpg')}" alt="第二张图" />
这里的 @me 会自动传递给函数的第一个参数。
在列表页 (list_article.htm):
{dede:list}
<img src="{dede:GetSecondImg([field:body/], '/images/default.jpg')}" alt="第二张图" />
{/dede:list}
这里需要明确传递 [field:body/] 作为参数。
优点:
- 代码复用:写一次,处处可用。
- 模板简洁:模板文件中的代码更清晰,易于维护。
- 逻辑分离:PHP逻辑和HTML模板分离,符合现代开发规范。
重要注意事项
- 图集录入方式:以上方法都基于文章的
body字段中包含完整的<img>标签,如果你的图集是通过织梦后台的“图集模型”上传的,body字段里确实会包含这些标签,如果你是手动把图片地址填在别的字段里,则需要相应调整。 - 性能考虑:在列表页使用
runphp或自定义函数会对每篇文章都执行一次正则匹配,如果列表文章数量非常多(上千篇),可能会对页面加载速度产生轻微影响,但对于大多数网站来说,这点性能影响可以忽略不计。 - 默认图片:强烈建议设置一个默认图片,以防文章没有图片或图片只有一张,导致页面布局错乱。
- 快速实现:直接使用 方法一 或 方法二。
- 长期维护:强烈推荐使用 方法三,将功能封装为自定义函数,这是最专业、最灵活的做法。


