方法1:使用数组统计(适用于ASCII字符)
这种方法利用字符的ASCII码作为数组的索引,统计每个字符出现的次数。
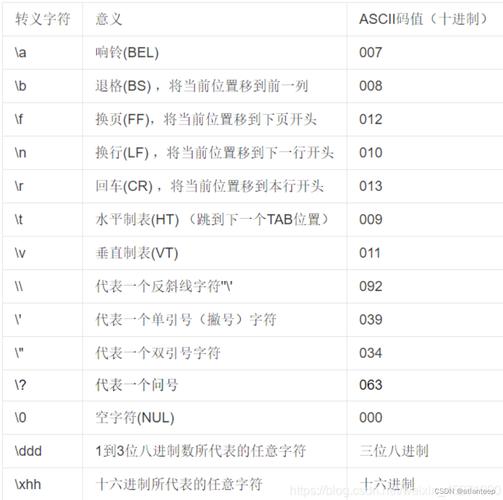
(图片来源网络,侵删)
#include <stdio.h>
#include <string.h>
#include <ctype.h> // 用于tolower()函数
void countCharacters(const char *str) {
int counts[256] = {0}; // ASCII字符范围0-255,初始化为0
// 遍历字符串,统计每个字符的出现次数
for (int i = 0; str[i] != '\0'; i++) {
unsigned char c = str[i]; // 避免负数索引问题
counts[c]++;
}
// 输出结果(仅打印出现次数大于0的字符)
printf("字符出现次数统计:\n");
for (int i = 0; i < 256; i++) {
if (counts[i] > 0) {
printf("'%c' (ASCII %d): %d次\n", (char)i, i, counts[i]);
}
}
}
int main() {
char input[100];
printf("请输入一个字符串: ");
fgets(input, sizeof(input), stdin); // 读取用户输入(包括空格)
input[strcspn(input, "\n")] = '\0'; // 去除fgets读取的换行符
countCharacters(input);
return 0;
}
说明:
- 数组大小:
counts[256]覆盖所有可能的ASCII字符(0-255)。 unsigned char:避免负数索引(某些编译器中char可能为负)。tolower():如果需要不区分大小写,可以在统计前将字符转为小写(tolower(c))。
方法2:使用哈希表(适用于任意字符集)
如果字符集很大(如Unicode),可以用哈希表(如C++的unordered_map或C的第三方库),以下是C语言模拟哈希表的实现:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define HASH_SIZE 256 // 简化版哈希表,实际应动态扩容
typedef struct {
char key;
int count;
} CharCount;
CharCount *hashTable[HASH_SIZE] = {NULL};
unsigned int hash(char c) {
return (unsigned char)c % HASH_SIZE;
}
void insertOrUpdate(char c) {
unsigned int index = hash(c);
CharCount *entry = hashTable[index];
// 查找是否已存在
while (entry != NULL) {
if (entry->key == c) {
entry->count++;
return;
}
entry = entry->next; // 假设链表冲突处理(此处简化)
}
// 不存在则插入新节点
CharCount *newEntry = malloc(sizeof(CharCount));
newEntry->key = c;
newEntry->count = 1;
newEntry->next = hashTable[index];
hashTable[index] = newEntry;
}
void printCounts() {
printf("字符出现次数统计:\n");
for (int i = 0; i < HASH_SIZE; i++) {
CharCount *entry = hashTable[i];
while (entry != NULL) {
printf("'%c': %d次\n", entry->key, entry->count);
entry = entry->next;
}
}
}
int main() {
char input[100];
printf("请输入一个字符串: ");
fgets(input, sizeof(input), stdin);
input[strcspn(input, "\n")] = '\0';
for (int i = 0; input[i] != '\0'; i++) {
insertOrUpdate(input[i]);
}
printCounts();
return 0;
}
说明:
- 哈希表冲突处理未完全实现(需链表或开放寻址)。
- 适用于非ASCII字符或大规模数据。
方法3:仅统计字母(不区分大小写)
如果只需要统计字母的出现次数:
#include <stdio.h>
#include <ctype.h>
void countLetters(const char *str) {
int counts[26] = {0}; // 26个字母
for (int i = 0; str[i] != '\0'; i++) {
char c = tolower(str[i]);
if (c >= 'a' && c <= 'z') {
counts[c - 'a']++;
}
}
printf("字母出现次数统计:\n");
for (int i = 0; i < 26; i++) {
if (counts[i] > 0) {
printf("'%c': %d次\n", 'a' + i, counts[i]);
}
}
}
int main() {
char input[100];
printf("请输入一个字符串: ");
fgets(input, sizeof(input), stdin);
input[strcspn(input, "\n")] = '\0';
countLetters(input);
return 0;
}
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 数组统计 | ASCII字符集,简单场景 | 高效,代码简单 | 内存固定,不适合大字符集 |
| 哈希表 | 任意字符集,大规模数据 | 灵活,动态扩展 | 实现复杂,需处理冲突 |
| 字母统计 | 仅需统计字母时 | 节省内存,专注字母 | 不支持其他字符 |
根据实际需求选择合适的方法,对于大多数C语言初学者,方法1(数组统计)是最常用且高效的解决方案。

(图片来源网络,侵删)


