在织梦中,文章内容主要存储在两个地方:
- (
description):在后台发布文章时填写的“字段,通常用于列表页的简介。 - 文章正文 (
body):文章的完整内容,存储在数据库的dede_addonarticle或dede_arctiny表中。
调用它们的标签分别是 {dede:field.description} 和 {dede:field.body}。
核心标签:{dede:field.body}
这是调用文章的标签,只能用在文章内容页模板(通常是 article_article.htm)。
基本用法:
{dede:field.body}
这行代码会直接输出当前文章的全部HTML内容,包括<p>、<img>、<h1>等所有标签。
常用功能与进阶用法
仅仅输出完整内容往往是不够的,我们通常需要对内容进行一些处理,比如截取摘要、去除HTML标签、调用图片等。
调用文章摘要 ({dede:field.description})
这个标签用于调用后台填写的文章摘要,同样只在内容页使用。
{dede:field.description}
截取文章正文作为摘要(非常常用)
如果后台没有填写摘要,或者你希望自动从正文中截取一部分作为摘要,可以使用 function='htmlspecialchars(@me)' 结合 cn_substr 函数。
语法:
{dede:field.body function='htmlspecialchars(cn_substr(@me, 200))'}

参数解释:
@me:代表当前字段的原始值,在这里就是文章的bodycn_substr:织梦的截取字符串函数。- 第一个参数
@me:要截取的字符串。 - 第二个参数
200:截取的字符长度(一个汉字、一个字母、一个标点都算一个字符)。
htmlspecialchars:将HTML特殊字符转换为HTML实体,这是一个非常重要的安全函数,可以防止XSS攻击,并确保<p>等标签在摘要中不被直接解析,而是以文本形式显示。
示例(在列表页或内容页调用200字摘要):
<p>{dede:field.body function='htmlspecialchars(cn_substr(@me, 200))'}</p>
去除HTML标签后截取
有时候你只需要纯文本的摘要,不希望保留任何HTML格式。
语法:
{dede:field.body function='htmlspecialchars(strip_tags(cn_substr(@me, 200))}'}
参数解释:
strip_tags:PHP函数,用于去除字符串中的所有HTML和PHP标签。cn_substr:再对去除标签后的纯文本进行截取。
示例(调用200字纯文本摘要):
<p>{dede:field.body function='htmlspecialchars(strip_tags(cn_substr(@me, 200))}'}</p>
调用文章中的第一张图片(缩略图)
这是一个非常流行的需求,比如在列表页显示文章的“图文”模式,自动提取正文的第一张图片作为缩略图。
语法:
{dede:field.body function='preg_replace("/<img[^>]+>/", "", @me)'}
注意: 这个标签是用来移除第一张图片的,而不是获取,获取第一张图片需要更复杂的处理,通常通过自定义函数实现。
正确的获取第一张图片的方法(需要修改模板文件):
- 打开织梦的
/include/helpers/extend.helper.php文件。 - 在文件末尾
?>之前,添加以下自定义函数:
// 获取文章body中的第一张图片地址
if (!function_exists('GetFirstImg'))
{
function GetFirstImg($body)
{
$preg = "/<img.*?src=[\'|\"](.*?)[\'|\"].*?[\/]?>/i";
preg_match_all($preg, $body, $match);
if (!empty($match[1]))
{
return $match[1][0]; // 返回第一张图片的src
}
return ''; // 如果没有图片,返回空
}
}
在你的模板(列表页或内容页)中,就可以这样调用:
<img src="{dede:field.body function='GetFirstImg(@me)'/}" alt="{dede:field.title/}" />
如果文章没有图片,上面的代码会输出一个空的 src 属性,我们可以结合三元运算符来优化:
{dede:field.name='imgurl' function='(@me ? "<img src=\'@me\' />" : "<img src=\'/images/default.jpg\' />")'}
(这里的 field.name='imgurl' 是一个变通方法,更规范的是直接调用函数)
更简洁的调用方式(在模板里直接使用函数): 如果你的织梦版本支持,可以直接在模板里调用PHP函数:
<img src="{dede:field.body function='GetFirstImg(@me)'/}" />
如果不行,就需要通过 {dede:php} 标签来调用,但这不推荐,因为效率较低。
内容分页
当一篇文章很长时,需要进行分页,织梦默认支持内容分页。
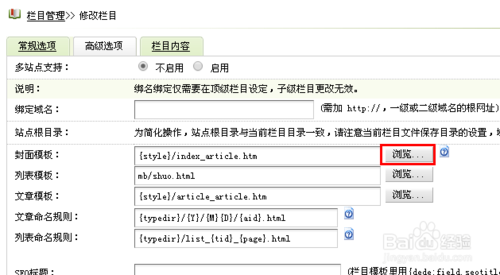
后台设置: 在后台“系统” -> “系统基本参数” -> “核心设置”中,确保“启用_arcmaker”是“是”。
模板中的分页标签:页模板 article_article.htm 中,需要将 {dede:field.body} 和分页标签放在一起。
标准写法:
<div class="article-content">
{dede:field.body/}
</div>
<div class="page-nav">
{dede:pagebreak/}
</div>
{dede:pagebreak/} 会自动生成上一页、下一页、页码等链接。
在列表页调用内容相关标签
虽然 {dede:field.body} 只能在内容页使用,但在列表页(list_article.htm)我们同样可以使用一些技巧来获取部分内容。
列表页常用字段标签:
{dede:list}:列表专用循环标签。{dede:field.title}。{dede:field.pubdate}:发布日期。{dede:field.description}:后台填写的)。{dede:field.arcurl}:文章链接地址。
在列表页调用正文摘要(如方法2所述):
{dede:list}
<h2><a href="[field:arcurl/]">[field:title/]</a></h2>
<p>[field:body function='htmlspecialchars(cn_substr(@me, 200))'/]...</p>
<span>[field:pubdate function="MyDate('Y-m-d', @me)"]</span>
{/dede:list}
注意: 在列表页循环 {dede:list} 内部,{dede:field.xxx} 应该写成 [field:xxx/] 的形式。
总结与最佳实践
| 需求 | 标签/代码 | 适用页面 | 说明 |
|---|---|---|---|
| 调用完整文章内容 | {dede:field.body} |
内容页 (article_article.htm) |
原样输出,包含所有HTML标签。 |
| 调用后台填写的摘要 | {dede:field.description} |
内容页 | 直接输出后台“字段的内容。 |
| 截取正文为摘要 | {dede:field.body function='htmlspecialchars(cn_substr(@me, 200))'} |
内容页、列表页 | 推荐用法,自动截取并防止XSS。 |
| 截取纯文本摘要 | {dede:field.body function='htmlspecialchars(strip_tags(cn_substr(@me, 200))}'} |
内容页、列表页 | 去除所有HTML标签后截取。 |
| 获取第一张图片 | 需添加自定义函数 GetFirstImg 到 extend.helper.php,再在模板调用 |
内容页、列表页 | 功能强大,但需要修改文件。 |
| 分页 | {dede:field.body/} + {dede:pagebreak/} |
内容页 | 必须同时使用才能生效。 |
重要提示:
- 安全性:始终使用
htmlspecialchars()函数处理从数据库中输出的、可能包含用户输入的内容,这是防止XSS攻击的关键。 - 模板语法页和列表页的标签语法差异,列表页在
{dede:list}循环内使用[field:xxx/]。 - 自定义函数:像获取第一张图片这类复杂功能,通过添加自定义函数是织梦最灵活、最规范的扩展方式。


