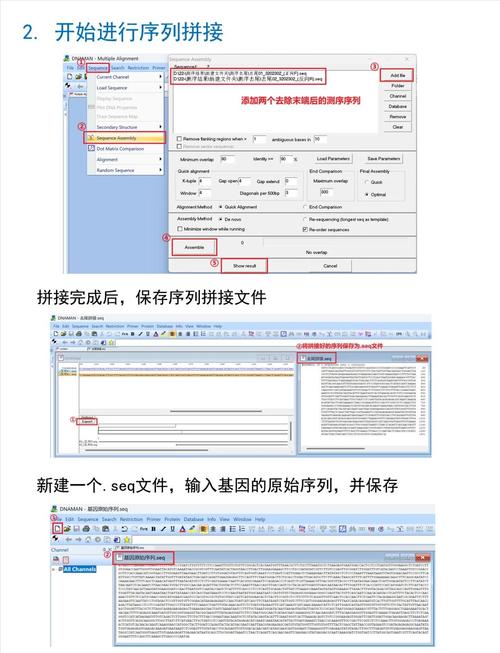
Huffman 解码的过程与编码正好相反,编码是根据字符频率构建 Huffman 树,然后将每个字符转换为其对应的二进制码,解码则是根据接收到的二进制码流,通过 Huffman 树一步步还原出原始的字符。

核心思想
解码器需要两样东西才能工作:
- Huffman 编码表:一个映射,告诉我们每个字符对应的二进制码是什么。
- Huffman 树:一个二叉树,从根节点开始,根据二进制码的
0或1向左或向右走,直到到达叶子节点,叶子节点上存储的就是原始字符。
在实际应用中,我们通常不会直接传递编码表,因为它可能比较冗长,更常见的做法是将 Huffman 树的结构和叶子节点的字符信息一起编码后发送给解码器,解码器首先根据这些信息重建 Huffman 树,然后才开始解码数据流。
解码过程分为两大步:
- 重建 Huffman 树
- 使用 Huffman 树解码数据
第 1 步:重建 Huffman 树
假设我们已经从编码数据中解析出了所有字符及其对应的 Huffman 编码(通过一个哈希表或结构体数组存储),我们可以利用这些信息来重建 Huffman 树。
重建算法:
- 创建一个空的 Huffman 树,只有一个根节点。
- 遍历每一个字符及其对应的编码。
- 对于每个编码,从根节点开始:
- 如果编码的当前位是
0,如果当前节点的左子节点不存在,则创建一个新的左子节点;然后移动到左子节点。 - 如果编码的当前位是
1,如果当前节点的右子节点不存在,则创建一个新的右子节点;然后移动到右子节点。
- 如果编码的当前位是
- 遍历完编码的所有位后,将当前字符存储在叶子节点中。
C 语言实现(树结构定义):
我们需要定义 Huffman 树的节点结构。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// Huffman 树的节点结构
typedef struct HuffmanNode {
char data; // 存储的字符 (仅叶子节点有效)
unsigned int frequency; // 频率 (编码时用,解码时可选)
struct HuffmanNode *left;
struct HuffmanNode *right;
} HuffmanNode;
// 创建一个新节点
HuffmanNode* createNode(char data, unsigned int freq) {
HuffmanNode* node = (HuffmanNode*)malloc(sizeof(HuffmanNode));
node->data = data;
node->frequency = freq;
node->left = node->right = NULL;
return node;
}
第 2 步:使用 Huffman 树解码数据
一旦我们重建了 Huffman 树,解码就非常直接了。

解码算法:
- 从 Huffman 树的根节点开始。
- 从输入的二进制位流中读取一位。
- 如果该位是
0,移动到当前节点的左子节点。 - 如果该位是
1,移动到当前节点的右子节点。 - 检查当前节点是否为叶子节点(即
left和right都为NULL)。- 如果是叶子节点:说明已经解码出一个完整的字符,将该字符输出,并将当前指针重置回根节点,准备解码下一个字符。
- 如果不是叶子节点:返回第 2 步,继续读取下一位。
- 重复以上步骤,直到所有的二进制位都被处理完毕。
完整的 C 语言解码示例
下面是一个完整的、可运行的 C 语言程序,为了简化,我们硬编码了编码后的数据和字符频率,并手动构建了 Huffman 树,在实际应用中,这部分信息会从文件或网络中读取并解析。
场景设定:
- 原始字符:
{'A', 'B', 'C', 'D'} - 频率:
{5, 1, 6, 3} - Huffman 编码:
C(频率最高):0A:10D:110B(频率最低):111
- 要解码的二进制码流:
11101110010
解码过程:
111->B0->C111->B0->C10->A0->C- (码流结束)
最终解码结果应为: BCBCAC
完整代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// Huffman 树的节点结构
typedef struct HuffmanNode {
char data;
unsigned int frequency;
struct HuffmanNode *left;
struct HuffmanNode *right;
} HuffmanNode;
// 创建一个新节点
HuffmanNode* createNode(char data, unsigned int freq) {
HuffmanNode* node = (HuffmanNode*)malloc(sizeof(HuffmanNode));
if (node == NULL) {
fprintf(stderr, "内存分配失败\n");
exit(1);
}
node->data = data;
node->frequency = freq;
node->left = node->right = NULL;
return node;
}
// 释放 Huffman 树的内存
void freeTree(HuffmanNode* root) {
if (root == NULL) {
return;
}
freeTree(root->left);
freeTree(root->right);
free(root);
}
/**
* @brief 解码函数
* @param root Huffman 树的根节点
* @param encodedString 编码后的二进制字符串 ("11101110010")
*/
void decode(HuffmanNode* root, const char* encodedString) {
printf("正在解码字符串: \"%s\"\n", encodedString);
HuffmanNode* currentNode = root;
if (!root || !encodedString) {
printf("输入无效或树为空,\n");
return;
}
printf("解码结果: ");
for (int i = 0; encodedString[i] != '\0'; i++) {
// 根据 0 或 1 移动
if (encodedString[i] == '0') {
currentNode = currentNode->left;
} else if (encodedString[i] == '1') {
currentNode = currentNode->right;
} else {
printf("\n错误: 无效的字符 '%c' 在编码字符串中,只允许 '0' 和 '1',\n", encodedString[i]);
return;
}
// 检查是否到达叶子节点
if (currentNode->left == NULL && currentNode->right == NULL) {
printf("%c", currentNode->data);
currentNode = root; // 重置到根节点,准备解码下一个字符
}
}
// 检查最后的状态,确保码流完整
if (currentNode != root) {
printf("\n错误: 编码字符串不完整,无法形成有效的字符。");
}
printf("\n");
}
int main() {
// --- 模拟从编码端获取的信息并重建 Huffman 树 ---
// 在实际应用中,这部分逻辑会更复杂,需要解析存储的树结构。
// 1. 创建叶子节点
HuffmanNode* nodeA = createNode('A', 5);
HuffmanNode* nodeB = createNode('B', 1);
HuffmanNode* nodeC = createNode('C', 6);
HuffmanNode* nodeD = createNode('D', 3);
// 2. 构建内部节点,形成树
// root
// / \
// / \
// n(AB) C(0)
// / \
// n(D) A(10)
// / \
//B D
// 创建 A 和 B 的父节点
HuffmanNode* nodeAB = createNode('\0', nodeA->frequency + nodeB->frequency);
nodeAB->left = nodeA;
nodeAB->right = nodeB;
// 创建 D 和 nodeAB 的父节点
HuffmanNode* nodeDAB = createNode('\0', nodeD->frequency + nodeAB->frequency);
nodeDAB->left = nodeD;
nodeDAB->right = nodeAB;
// 创建根节点
HuffmanNode* root = createNode('\0', nodeDAB->frequency + nodeC->frequency);
root->left = nodeDAB;
root->right = nodeC;
// --- 树构建完毕 ---
// 要解码的字符串
const char* encodedString = "11101110010";
// 调用解码函数
decode(root, encodedString);
// 释放树的内存
freeTree(root);
return 0;
}
运行结果
正在解码字符串: "11101110010"
解码结果: BCBCAC实际应用中的注意事项
-
元数据:解码器如何知道如何重建树?编码器通常会在压缩数据前写入一些元数据,
- 字符的种类数。
- 每个字符及其频率。
- 或者,更高效地,对 Huffman 树进行前序遍历编码(遇到内部节点存
0,遇到叶子节点存1和字符本身),解码器读取这些元数据后,可以精确地重建出和编码端完全相同的树。
-
位流处理:上面的例子使用字符串
"111..."来表示二进制流,这在概念上很清晰,但在实际文件或网络I/O中,数据是以字节(8位)为单位的,你需要一个机制来逐位地从字节流中读取数据,这通常涉及一个位缓冲区(bit buffer)和当前已读取的位数计数器。 -
错误处理:如果接收到的数据在传输过程中损坏,可能会导致解码器在 Huffman 树上走到一个不存在的路径(即遇到一个非法的
0或1指令),健壮的解码器需要能够检测到这种情况并报告错误,而不是崩溃或产生无意义的输出,上面的代码在码流不完整时会有一个简单的错误提示。
这个例子为你展示了 Huffman 解码的核心逻辑,要将其应用于真实场景,你还需要添加元数据的解析和高效的位流读取功能。


