什么是链表?
想象一列火车:
(图片来源网络,侵删)
- 火车头:指向第一节车厢。
- 每节车厢:都包含货物(数据)和一个连接钩(指向下一节车厢的指针)。
- 最后一节车厢:它的连接钩是空的(指向
NULL),表示列车的末尾。
在 C 语言中,链表就是由这样一系列“节点”(Node)组成的线性集合,每个节点都包含两部分:
- 数据域:存储实际的数据。
- 指针域:存储指向下一个节点的内存地址。
链表的第一个节点被称为头节点,最后一个节点的指针域指向 NULL。
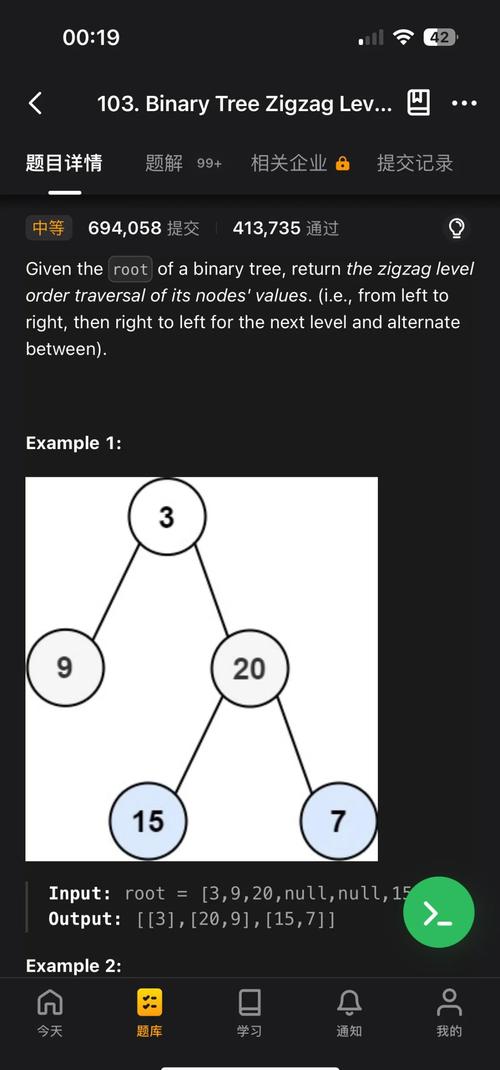
链表的类型
根据指针的指向,链表可以分为几种常见的类型:
- 单向链表:最常见的形式,每个节点只包含一个指向下一个节点的指针,只能从头到尾遍历。
- 双向链表:每个节点包含两个指针,一个指向前一个节点,一个指向后一个节点,可以双向遍历,插入和删除操作更灵活。
- 循环链表:单向或双向链表的最后一个节点不指向
NULL,而是指向头节点,形成一个环。
本教程将重点讲解单向链表,因为它是理解其他类型链表的基础。
(图片来源网络,侵删)
单向链表的实现
1 定义节点结构
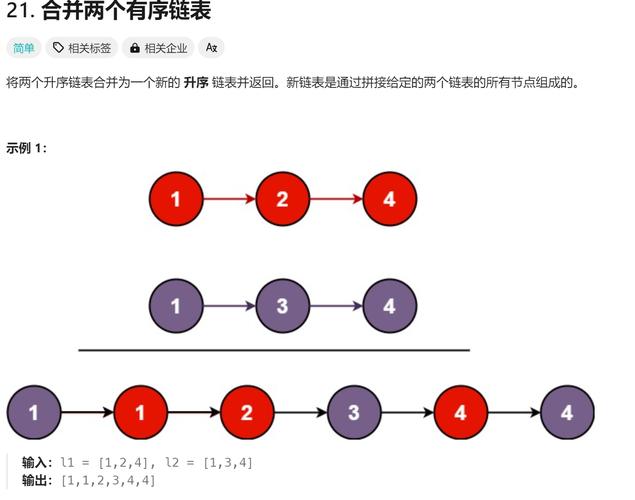
我们需要定义一个结构体来表示链表的节点。
#include <stdio.h>
#include <stdlib.h> // 用于 malloc 和 free
// 定义节点结构体
typedef struct Node {
int data; // 数据域,这里以存储整数为例
struct Node* next; // 指针域,指向下一个节点
} Node;
typedef为struct Node创建了一个别名Node,使代码更简洁。struct Node* next;是关键,它是一个指向同类型结构体 (Node) 的指针。
2 创建新节点
我们需要一个函数来动态创建新节点,并初始化它的数据域和指针域。
// 创建一个新节点
Node* createNode(int data) {
// 1. 为新节点分配内存
Node* newNode = (Node*)malloc(sizeof(Node));
// 2. 检查内存是否分配成功
if (newNode == NULL) {
printf("内存分配失败!\n");
exit(1); // 退出程序
}
// 3. 初始化新节点
newNode->data = data;
newNode->next = NULL; // 新节点的 next 指针初始为 NULL
return newNode;
}
malloc(sizeof(Node))在堆上为一个新的节点分配了足够的内存空间。- 务必检查
malloc的返回值,以防内存不足导致程序崩溃。 - 新创建的节点默认是链表的末尾,
next指向NULL。
链表的基本操作
1 在链表头部插入节点
这是最简单的插入操作,新节点会成为新的头节点。
// 在链表头部插入节点
Node* insertAtHead(Node* head, int data) {
// 创建新节点
Node* newNode = createNode(data);
// 将新节点的 next 指向原来的头节点
newNode->next = head;
// 新节点成为新的头节点
return newNode;
}
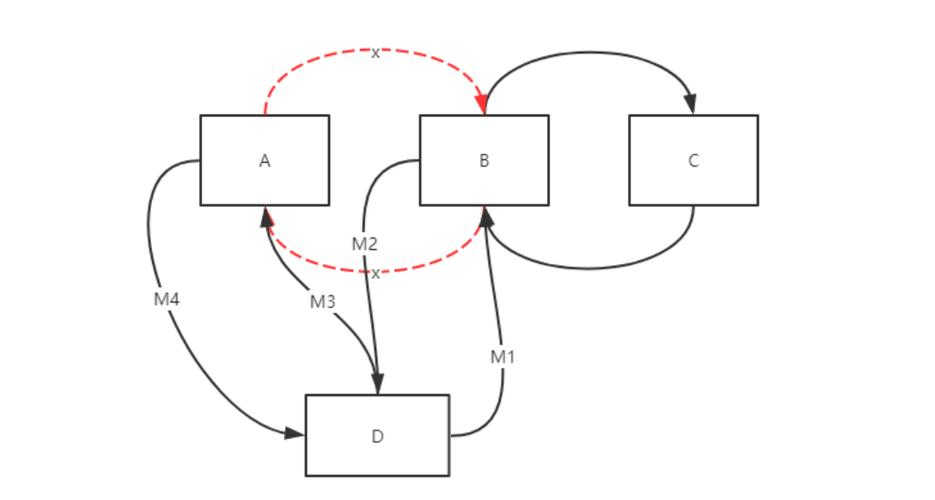
2 在链表尾部插入节点
需要遍历整个链表,找到最后一个节点,然后将新节点连接到它后面。
(图片来源网络,侵删)
// 在链表尾部插入节点
Node* insertAtTail(Node* head, int data) {
// 创建新节点
Node* newNode = createNode(data);
// 如果链表为空,新节点就是头节点
if (head == NULL) {
return newNode;
}
// 遍历链表,找到最后一个节点
Node* current = head;
while (current->next != NULL) {
current = current->next;
}
// 将最后一个节点的 next 指向新节点
current->next = newNode;
// 头节点不变,返回原头节点
return head;
}
3 在指定位置插入节点
这个操作比较复杂,需要找到要插入位置的前一个节点。
// 在指定位置插入节点 (位置从 0 开始)
Node* insertAtPosition(Node* head, int data, int position) {
// 处理非法位置
if (position < 0) {
printf("非法位置!\n");
return head;
}
// 如果位置是 0,等同于在头部插入
if (position == 0) {
return insertAtHead(head, data);
}
// 创建新节点
Node* newNode = createNode(data);
// 遍历到要插入位置的前一个节点
Node* current = head;
int currentPos = 0;
while (current != NULL && currentPos < position - 1) {
current = current->next;
currentPos++;
}
// 如果位置超出链表长度,则插入到尾部
if (current == NULL) {
printf("位置超出链表长度,已插入到尾部,\n");
// 需要重新找到尾部,这里复用 insertAtTail 逻辑
// 为了简单,我们直接在这里找到尾部
if (head == NULL) {
return newNode;
}
Node* last = head;
while (last->next != NULL) {
last = last->next;
}
last->next = newNode;
return head;
}
// 插入新节点
// A -> B, 插入 C 到 A 和 B 之间
// C->next = A->next (B)
// A->next = C
newNode->next = current->next;
current->next = newNode;
return head;
}
4 删除节点
删除节点也需要找到其前一个节点,并修改其 next 指针,删除头节点是特殊情况。
// 删除值为 data 的第一个节点
Node* deleteNode(Node* head, int data) {
if (head == NULL) {
printf("链表为空,无法删除,\n");
return NULL;
}
// 如果要删除的是头节点
if (head->data == data) {
Node* temp = head; // 临时保存头节点
head = head->next; // 头节点指向下一个节点
free(temp); // 释放旧头节点的内存
return head; // 返回新的头节点
}
// 遍历找到要删除节点的前一个节点
Node* current = head;
while (current->next != NULL && current->next->data != data) {
current = current->next;
}
// 如果找到了要删除的节点
if (current->next != NULL) {
Node* temp = current->next; // 临时保存要删除的节点
current->next = temp->next; // 跳过要删除的节点
free(temp); // 释放内存
printf("删除了值为 %d 的节点,\n", data);
} else {
printf("未找到值为 %d 的节点,\n", data);
}
return head;
}
5 遍历并打印链表
从头节点开始,沿着 next 指针一直走到 NULL。
// 打印链表
void printList(Node* head) {
if (head == NULL) {
printf("链表为空,\n");
return;
}
Node* current = head;
printf("链表: ");
while (current != NULL) {
printf("%d -> ", current->data);
current = current->next;
}
printf("NULL\n");
}
6 释放整个链表的内存
为了避免内存泄漏,在使用完链表后,必须释放所有节点分配的内存。
// 释放整个链表
void freeList(Node* head) {
Node* current = head;
Node* nextNode;
while (current != NULL) {
nextNode = current->next; // 先保存下一个节点的地址
free(current); // 释放当前节点
current = nextNode; // 移动到下一个节点
}
printf("链表已释放,\n");
}
完整示例代码
下面是一个将所有操作整合在一起的完整示例。
#include <stdio.h>
#include <stdlib.h>
// 定义节点结构体
typedef struct Node {
int data;
struct Node* next;
} Node;
// 函数声明
Node* createNode(int data);
Node* insertAtHead(Node* head, int data);
Node* insertAtTail(Node* head, int data);
Node* insertAtPosition(Node* head, int data, int position);
Node* deleteNode(Node* head, int data);
void printList(Node* head);
void freeList(Node* head);
int main() {
Node* head = NULL; // 初始化一个空链表
// 在头部插入
head = insertAtHead(head, 10);
printList(head);
// 在尾部插入
head = insertAtTail(head, 20);
printList(head);
// 再次在头部插入
head = insertAtHead(head, 5);
printList(head);
// 在指定位置插入 (位置 1)
head = insertAtPosition(head, 15, 1);
printList(head);
// 删除一个节点
head = deleteNode(head, 10);
printList(head);
// 删除不存在的节点
head = deleteNode(head, 99);
printList(head);
// 释放链表内存
freeList(head);
head = NULL; // 好的编程习惯,将头指针置为 NULL
return 0;
}
// --- 函数实现 (见上文) ---
// ... (将上面所有函数的实现代码粘贴到这里) ...
链表 vs. 数组
| 特性 | 链表 | 数组 |
|---|---|---|
| 内存空间 | 不连续,动态分配 | 连续,静态或动态分配 |
| 大小 | 动态,可随时增减 | 固定(静态)或可调整(动态) |
| 插入/删除 | 高效 (O(1) 头部,O(n) 中间/尾部) | 低效 (O(n),需要移动大量元素) |
| 访问元素 | 低效 (O(n),需要遍历) | 高效 (O(1),通过索引直接访问) |
| 内存开销 | 每个节点都需要额外的指针空间 | 没有额外开销 |
| 缓存性能 | 较差,节点分散在内存中 | 较好,数据连续,利于CPU缓存 |
链表是 C 语言中必须掌握的数据结构,它的核心在于利用指针将内存中不连续的数据块串联起来,理解如何创建节点、插入节点、删除节点以及遍历和释放链表,是迈向更复杂数据结构(如树、图)的重要一步,虽然链表在某些操作上不如数组高效,但其动态性和插入删除的灵活性使其在许多场景下成为不可或缺的工具。


