最可能的情况:拼写错误,应该是 float
float 是C语言中最基本、最常用的单精度浮点数类型。
(图片来源网络,侵删)
- 用途:用于存储带有小数的数字,
14,-0.5,0。 - 大小:通常占用 4个字节(32位)的内存空间。
- 精度:大约提供 6-9位 有效数字,这意味着对于像
6789这样的数字,它可能无法精确存储所有小数位。
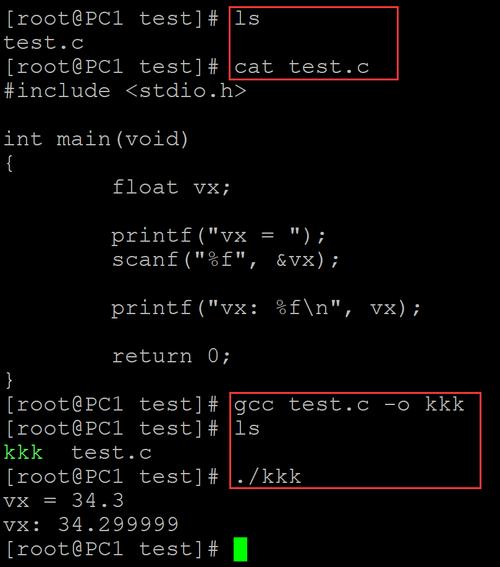
示例代码:
#include <stdio.h>
int main() {
// 声明一个 float 类型的变量
float pi = 3.14159f; // 注意:f 后缀表示这是一个 float 常量,而不是 double
float price = 19.99;
printf("The value of pi is: %f\n", pi);
printf("The price is: %.2f\n", price); // %.2f 表示保留两位小数输出
return 0;
}
输出:
The value of pi is: 3.141590
The price is: 19.99另一种常见情况:拼写错误,应该是 double
double 是C语言中另一个非常重要的双精度浮点数类型。
- 用途:和
float一样用于存储小数,但精度更高。 - 大小:通常占用 8个字节(64位)的内存空间。
- 精度:大约提供 15-17位 有效数字,在大多数科学计算和工程应用中,
double是首选。
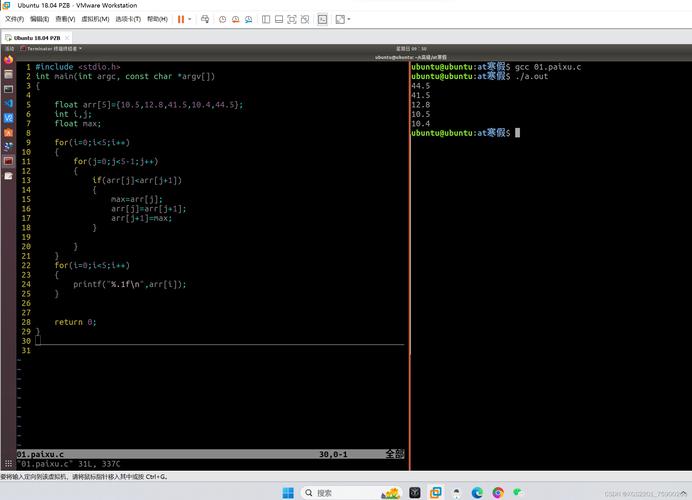
示例代码:
(图片来源网络,侵删)
#include <stdio.h>
int main() {
double precise_pi = 3.141592653589793;
double large_number = 123456789.123456789;
printf("Precise pi: %.15f\n", precise_pi);
printf("Large number: %.9f\n", large_number);
return 0;
}
输出:
Precise pi: 3.141592653589793
Large number: 123456789.123456789可能是概念混淆:float 和 double 的区别
很多初学者会混淆 float 和 double,它们的主要区别在于精度和内存占用。
| 特性 | float (单精度) |
double (双精度) |
|---|---|---|
| 关键字 | float |
double |
| 内存大小 | 4 字节 (32位) | 8 字节 (64位) |
| 精度 | 约 6-9 位有效数字 | 约 15-17 位有效数字 |
| 速度 | 在某些旧架构上可能更快 | 现代CPU上通常和float一样快或更快 |
| 后缀 | f 或 F (14f) |
l 或 L (14L) |
如果你需要高精度,或者不确定该用哪个,默认使用 double 是一个更安全的选择,只有在内存极其受限或有特殊性能要求时,才考虑使用 float。
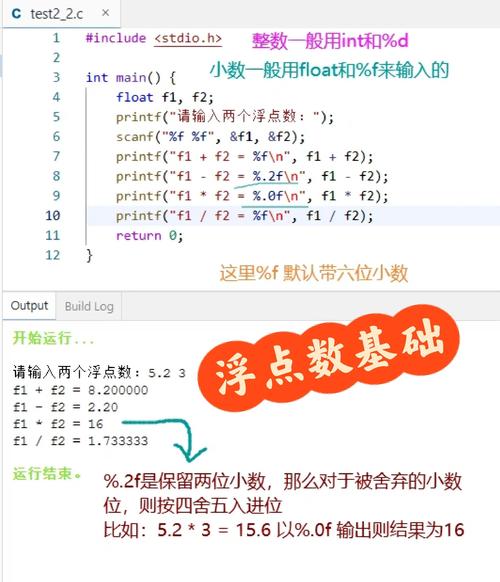
不太可能但可能的情况:long double
long double 是C语言中提供的精度最高的浮点数类型,其具体大小和精度取决于编译器和操作系统(通常为80位或128位)。
(图片来源网络,侵删)
long double very_precise_value = 1.2345678901234567890L;
(floatfloat) 的错误分析
如果您尝试这样写代码:
// 错误的写法 floatfloat myVar;
编译器会报错,因为它不认识 floatfloat 这个类型,这就像说“一个红色的红色的苹果”一样,在语法上是冗余且错误的。
| 您可能想输入的 | 正确的写法 | 解释 |
|---|---|---|
floatfloat |
float |
单精度浮点数,基础类型。 |
floatfloat |
double |
双精度浮点数,精度更高,更常用。 |
float float |
float |
中间多了一个空格,是错误的。 |
floatfloat |
long double |
最高精度的浮点数类型。 |
希望这个解释能帮助您!如果您能提供更多上下文(比如您是在哪里看到 "floatfloat" 的),我可以给您更精确的解答。


