浮点数
在计算机中,处理带有小数点的数字(如 3.14, -0.001, 1000.5)时,使用的是“浮点数”类型,这个名字来源于科学记数法中的“小数点位置是浮动的”。
(图片来源网络,侵删)
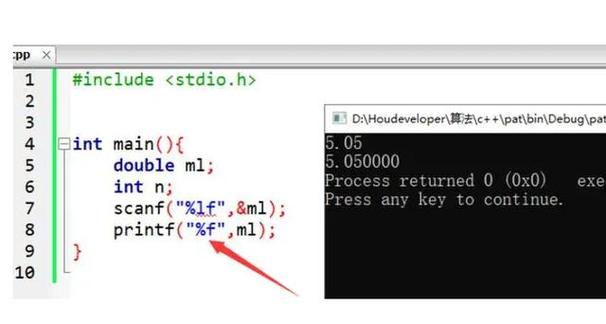
数字 45 可以表示为:
2345 * 10^2345 * 10^112345 * 10^3
这里的 10 是基数,2、1、3 是指数,而 2345、345、12345 是尾数或有效数字,计算机就是用类似的方式来存储和计算浮点数的。
float vs double:关键区别
float 和 double 的主要区别在于它们存储数字所需的内存空间大小,这直接决定了它们的精度和表示范围。
| 特性 | float (单精度浮点数) |
double (双精度浮点数) |
|---|---|---|
| 关键字 | float |
double |
| 内存大小 | 4 字节 (32 位) | 8 字节 (64 位) |
| 精度 (有效数字) | 约 6-7 位 十进制数字 | 约 15-16 位 十进制数字 |
| 指数范围 | 较小 | 较大 |
| 表示范围 | 较小 | 较大 |
| 速度 | 通常比 double 稍快 |
在现代 CPU 上,与 float 速度几乎相同 |
| 后缀 | f 或 F (14f) |
l 或 L (3.1415926535L) |
| 默认类型 | 当你写 14 时,C 语言默认将其视为 double 类型。 |
当你写 14 时,C 语言默认将其视为 double 类型。 |
内存大小与精度
这是两者最核心的区别,更大的内存空间意味着可以存储更多的有效数字和更大的指数,从而提供更高的精度和更大的表示范围。
(图片来源网络,侵删)
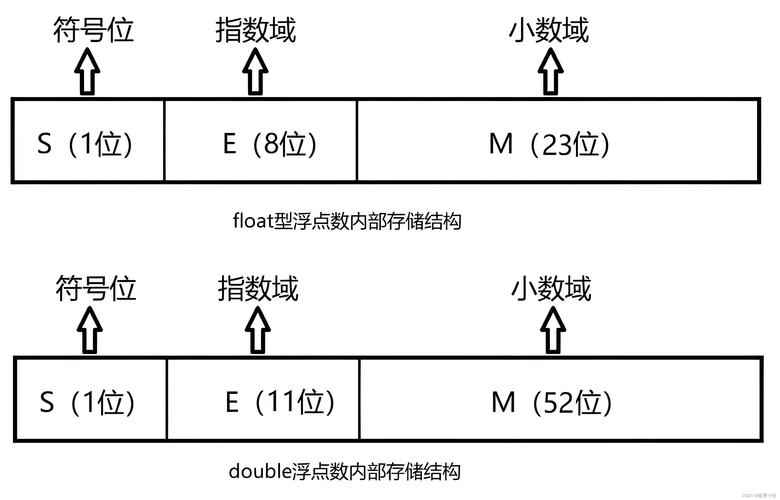
float (4 字节 / 32 位)
根据 IEEE 754 标准,这 32 位被分配为:
- 1 位:符号位 (正或负)
- 8 位:指数位
- 23 位:尾数位 (有效数字)
double (8 字节 / 64 位)
同样根据 IEEE 754 标准,这 64 位被分配为:
- 1 位:符号位 (正或负)
- 11 位:指数位
- 52 位:尾数位 (有效数字)
double 拥有比 float 多一倍的指数位和超过两倍的尾数位,因此它的精度和范围都远超 float。
精度示例
让我们通过一个例子来看看精度的差异。
#include <stdio.h>
int main() {
float f_num = 123456789.123456789; // 赋予一个长数字
double d_num = 123456789.123456789;
printf("Float value: %.10f\n", f_num); // 打印 float,保留10位小数
printf("Double value: %.10f\n", d_num); // 打印 double,保留10位小数
return 0;
}
可能的输出:
Float value: 123456792.0000000000 // 注意,从第7位开始就严重失真了
Double value: 123456789.1234567139 // 精度非常高,只有最后几位有微小误差分析:
float类型无法精确存储123456789这个数,它只能保证前 6-7 位是准确的,后面的数字都被截断或四舍五入了,导致精度严重丢失。double类型则能存储这个数的大部分信息,直到第 15 位左右才开始出现微小的舍入误差。
何时使用 float,何时使用 double?
这是一个非常实际的问题。
使用 double 的情况 (更推荐)
- 默认选择:如果你不确定,或者对精度有要求,总是优先使用
double。 - 科学计算、金融计算:任何需要高精度的场景,如物理模拟、工程计算、货币计算等。
- 大多数应用程序:在现代计算机上,
double和float的性能差异已经微乎其微,而double带来的精度提升是巨大的,使用double可以避免很多潜在的精度陷阱。
使用 float 的情况
- 内存极度受限:在嵌入式系统、移动设备或需要处理海量数据(如 3D 图形中的顶点坐标)时,使用
float可以节省一半的内存。 - 性能关键且数据量巨大:在某些旧的或特定的硬件架构上,
float的计算速度可能比double快,当处理数百万个浮点数时,这种微小的速度差异可能会累积起来,但在现代 x86/ARM 架构上,通常没有明显区别。 - 图形编程 (GPU):GPU 早期对
float的硬件支持更好,虽然现在也普遍支持double,但在很多图形 API 中,float仍然是默认选项。
代码示例与注意事项
a. 字面量后缀
如果你想声明一个 float 类型的变量,必须在小数后加上 f 或 F,否则编译器会将其视为 double 类型,然后在进行赋值时可能会产生警告(从 double 转换到 float 可能会丢失数据)。
float a = 3.14; // 可能产生警告:将 double 赋给 float float b = 3.14f; // 正确,明确表示这是一个 float float c = 3.14F; // 同样正确 double d = 3.14; // 正确,3.14 默认就是 double double e = 3.14; // 正确 double f = 3.14l; // 正确,l 或 L 后缀表示 long double
b. 打印格式
- 打印
float或double时,都使用%f格式说明符。 %f会将数字作为double来处理,这对于float来说是完全安全的,因为float可以无损地转换为double(double的精度足以容纳float的所有信息)。- 如果你有一个
float变量,想用%f打印,需要先将其转换为double(这通常是隐式发生的)。
float my_float = 5.67;
printf("Value is: %f\n", (double)my_float); // 显式转换,更清晰
printf("Value is: %f\n", my_float); // 隐式转换,也能正常工作
c. 浮点数不精确性
重要提醒: 由于计算机使用二进制存储,而很多十进制小数在二进制中是无限循环的(就像 1/3 在十进制中是 0.333... 一样),所以浮点数本质上就是不精确的,我们永远不要用 来比较两个浮点数是否相等。
#include <stdio.h>
#include <math.h> // 用于 fabs 函数
int main() {
double a = 0.1 + 0.2;
double b = 0.3;
// 错误的比较方式!
if (a == b) {
printf("a equals b\n"); // 这行代码很可能不会执行
} else {
printf("a does NOT equal b\n"); // 这行代码很可能会执行
}
// 正确的比较方式:判断它们的差值是否在一个很小的“epsilon”范围内
if (fabs(a - b) < 1e-9) { // 1e-9 是一个非常小的数
printf("a is approximately equal to b\n"); // 这行代码会执行
}
return 0;
}
输出:
a does NOT equal b
a is approximately equal to b| 特性 | float |
double |
|---|---|---|
| 一句话总结 | 低精度,节省内存 | 高精度,推荐使用 |
| 适用场景 | 嵌入式、内存/性能敏感的图形学 | 默认选择、科学计算、金融、绝大多数应用 |
| 核心原则 | 除非有特殊需求(内存或性能),否则永远选择 double,它能以极小的代价(几乎没有性能损失)换来巨大的精度提升,避免许多难以调试的 bug。 |


