- 冒泡排序 - 最简单,但效率最低。
- 选择排序 - 思路清晰,效率也不高。
- 插入排序 - 对于小规模或基本有序的数据效率较好。
- 标准库函数
qsort()- 强烈推荐,在实际开发中应该使用它,因为它经过高度优化且非常方便。
准备工作:打印数组的辅助函数
在展示排序算法之前,我们先写一个辅助函数,用于打印数组内容,方便我们观察排序前后的变化。
(图片来源网络,侵删)
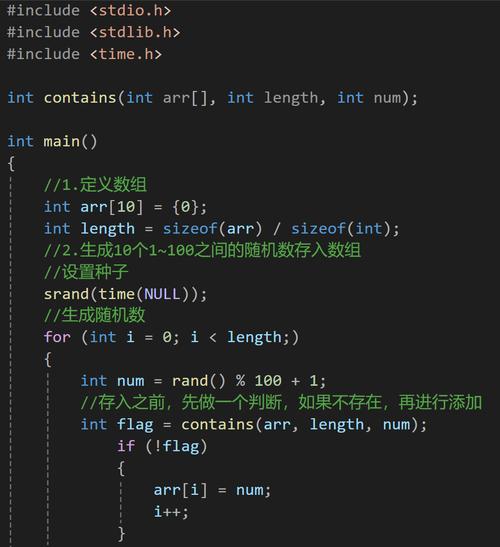
#include <stdio.h>
// 打印数组的函数
void print_array(int arr[], int size) {
for (int i = 0; i < size; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
冒泡排序
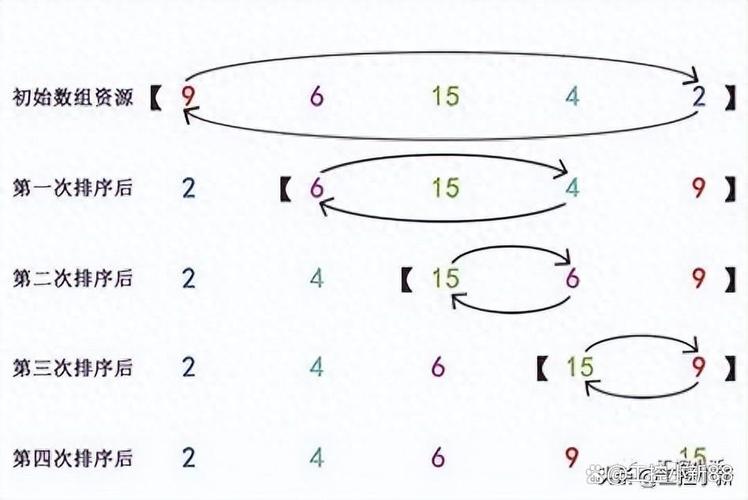
思想: 重复地遍历要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来,遍历数列的工作是重复进行的,直到没有再需要交换的元素为止,这意味着该数列已经排序完成,就像水底的气泡一样,最大的元素会“冒泡”到数列的顶端。
特点:
- 优点:代码简单,易于理解和实现。
- 缺点:时间复杂度为 O(n²),当数据量大时,性能极差。
C语言实现:
void bubble_sort(int arr[], int size) {
int i, j, temp;
// 外层循环控制排序的轮数
for (i = 0; i < size - 1; i++) {
// 内层循环进行相邻元素的比较和交换
// 每一轮内层循环后,最大的元素会“冒泡”到最后,所以内层循环可以减少i次
for (j = 0; j < size - 1 - i; j++) {
// 如果前一个元素比后一个元素大,则交换它们
if (arr[j] > arr[j + 1]) {
// 交换 arr[j] 和 arr[j+1]
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
int main() {
int data[] = {64, 34, 25, 12, 22, 11, 90};
int n = sizeof(data) / sizeof(data[0]);
printf("排序前的数组: ");
print_array(data, n);
bubble_sort(data, n);
printf("排序后的数组: ");
print_array(data, n);
return 0;
}
输出:

(图片来源网络,侵删)
排序前的数组: 64 34 25 12 22 11 90
排序后的数组: 11 12 22 25 34 64 90 选择排序
思想: 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾,以此类推,直到所有元素均排序完毕。
特点:
- 优点:代码也相对简单,交换次数少于冒泡排序。
- 缺点:时间复杂度也是 O(n²),性能同样不高。
C语言实现:
void selection_sort(int arr[], int size) {
int i, j, min_idx, temp;
// 一遍一遍地移动边界
for (i = 0; i < size - 1; i++) {
// 找到未排序部分的最小元素的索引
min_idx = i;
for (j = i + 1; j < size; j++) {
if (arr[j] < arr[min_idx]) {
min_idx = j;
}
}
// 将找到的最小元素与当前位置的元素交换
if (min_idx != i) {
temp = arr[i];
arr[i] = arr[min_idx];
arr[min_idx] = temp;
}
}
}
int main() {
int data[] = {64, 25, 12, 22, 11, 90, 34};
int n = sizeof(data) / sizeof(data[0]);
printf("排序前的数组: ");
print_array(data, n);
selection_sort(data, n);
printf("排序后的数组: ");
print_array(data, n);
return 0;
}
输出:
(图片来源网络,侵删)
排序前的数组: 64 25 12 22 11 90 34
排序后的数组: 11 12 22 25 34 64 90 插入排序
思想: 通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入,插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序)。
特点:
- 优点:对于小规模数据或基本有序的数据,效率非常高。
- 缺点:时间复杂度仍为 O(n²),不适合大规模数据。
C语言实现:
void insertion_sort(int arr[], int size) {
int i, key, j;
for (i = 1; i < size; i++) {
key = arr[i]; // 当前要插入的元素
j = i - 1; // key前一个元素的索引
// 将大于key的元素向后移动
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j = j - 1;
}
// 将key插入到正确的位置
arr[j + 1] = key;
}
}
int main() {
int data[] = {12, 11, 13, 5, 6};
int n = sizeof(data) / sizeof(data[0]);
printf("排序前的数组: ");
print_array(data, n);
insertion_sort(data, n);
printf("排序后的数组: ");
print_array(data, n);
return 0;
}
输出:
排序前的数组: 12 11 13 5 6
排序后的数组: 5 6 11 12 13 使用标准库函数 qsort() (强烈推荐)
在实际开发中,不要自己从头实现排序算法,除非有特殊需求,C语言的标准库提供了一个非常强大和高效的排序函数 qsort()。
qsort() 函数位于 <stdlib.h> 头文件中。
函数原型:
void qsort(void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *));
参数说明:
base: 指向要排序的数组的第一个元素的指针。nmemb: 数组中元素的数量。size: 数组中每个元素的大小(以字节为单位),可以使用sizeof运算符获取。compar: 指向比较函数的指针,这个函数决定了排序的顺序。
比较函数 compar 的规则:
- 它接收两个参数,都是指向要比较的元素的指针
const void *。 - 返回一个整数:
- 返回负值:表示第一个元素小于第二个元素。
- 返回零:表示两个元素相等。
- 返回正值:表示第一个元素大于第二个元素。
C语言实现:
我们需要为 qsort 编写一个比较函数。
#include <stdlib.h> // 必须包含此头文件
// 比较函数,用于升序排序
int compare_ints(const void* a, const void* b) {
int arg1 = *(const int*)a;
int arg2 = *(const int*)b;
if (arg1 < arg2) return -1;
if (arg1 > arg2) return 1;
return 0;
}
int main() {
int data[] = {64, 34, 25, 12, 22, 11, 90};
int n = sizeof(data) / sizeof(data[0]);
printf("排序前的数组: ");
print_array(data, n);
// 使用 qsort 进行排序
qsort(data, n, sizeof(int), compare_ints);
printf("排序后的数组: ");
print_array(data, n);
return 0;
}
输出:
排序前的数组: 64 34 25 12 22 11 90
排序后的数组: 11 12 22 25 34 64 90 如何降序排序?
只需修改 compare_ints 函数的逻辑即可:
// 比较函数,用于降序排序
int compare_ints_desc(const void* a, const void* b) {
int arg1 = *(const int*)a;
int arg2 = *(const int*)b;
if (arg1 > arg2) return -1; // 注意这里的逻辑反了
if (arg1 < arg2) return 1;
return 0;
}
然后在 qsort 调用时使用 compare_ints_desc。
总结与对比
| 算法 | 平均时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 稳定性 | 适用场景 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n²) | O(n²) | O(1) | 稳定 | 教学,小规模数据 |
| 选择排序 | O(n²) | O(n²) | O(1) | 不稳定 | 教学 |
| 插入排序 | O(n²) | O(n²) | O(1) | 稳定 | 小规模数据或基本有序的数据 |
qsort() |
O(n log n) | O(n log n) | O(log n) | 不稳定 | 通用、首选,几乎所有场景 |
核心建议:
- 学习和面试:务必掌握冒泡、选择、插入排序的原理和代码,这是理解排序算法的基础。
- 实际项目开发:直接使用
qsort(),它是由C标准库提供的,经过了充分测试和高度优化,性能可靠,能让你专注于业务逻辑本身,而不是重复造轮子。


