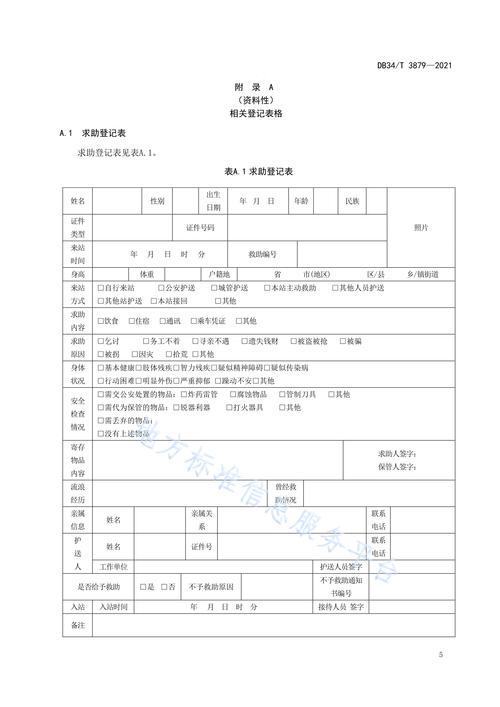
核心概念:采集的“三要素”
在配置任何采集规则之前,你必须先理解这三个核心要素,它们是所有采集规则的基石:

- 目标网址:你要从哪个网站采集内容?这通常是一个包含多个列表页的网址,
https://www.example.com/news/list-1.html。 - 列表页规则:如何从“目标网址”中找到所有文章的链接地址?列表页就是存放许多文章标题和链接的页面,你需要告诉 DedeCMS 如何在这个页面上“抓取”到每一篇文章的 URL。
- 内容页规则:如何从上一步抓取到的“文章链接”中,提取出文章的标题、作者、来源、正文、图片等信息?内容页就是单篇文章的页面。
流程图:
目标网址 -> 列表页规则 -> 抓取到 N 个文章链接 -> 对每个链接应用内容页规则 -> 提取出文章详情 -> 保存到你的网站
采集规则的详细配置步骤
我们以 DedeCMS 后台的 采集 -> 采集管理 -> 增加新采集 为路径,一步步讲解。
第 1 步:基本配置
首先填写采集任务的名称、目标网址等基本信息。
- 任务名称:给你的采集任务起个名字,方便日后管理,如“XX科技新闻采集”。
- 目标网址:填写你要采集的网站的根目录 URL,
https://www.example.com/。 - 列表页 URL:填写包含文章列表的具体页面 URL,这里可以用通配符 来代表页码,
https://www.example.com/news/list-*.html会被替换成 1, 2, 3... 等数字,DedeCMS 会自动抓取这些页面。 - 起始 URL:通常和列表页 URL 一样,或者直接填写第一页的 URL。
- 采集栏目:选择采集到的文章要存放到你网站的哪个栏目下。请务必选择一个与采集内容类型相符的栏目。
- 作者设置:
- 来源网址:将采集的网站地址作为文章来源。
- 固定来源:手动输入一个固定的来源名称,如“XX新闻网”。
- 抓取来源页的特定位置抓取来源信息(需要配置内容页规则)。
- 发布时间:
- 当前时间:使用采集时的服务器时间。
- 抓取发布时间页的特定位置抓取发布时间(需要配置内容页规则)。
- 是否下载远程图片:强烈建议开启,开启后,文章中的图片会被下载到你网站的
uploads目录下,并替换为本地路径,防止对方网站图片失效或丢失。 - 是否启用远程附件:如果文章包含附件(如 PDF, ZIP),可以开启并下载到本地。
第 2 步:配置列表页规则
这是最关键的一步,目的是从列表页中提取出所有文章的链接。
- 点击“选择列表页”,在弹出的窗口中填写列表页的 URL(就是你上面填写的
https://www.example.com/news/list-*.html),然后点击“浏览”。 - 分析列表页结构:
- 打开列表页的源代码(浏览器右键 -> “查看网页源代码”)。
- 找到包裹每篇文章链接的 HTML 标签,每篇文章都在一个
<li>标签里,链接是<a>
- 配置列表规则:
- 列表起始标记:输入包裹所有文章列表的起始 HTML 标签,如果所有文章都在
<div class="news_list">和</div>之间,这里就填<div class="news_list">。 - 列表结束标记:输入包裹所有文章列表的结束 HTML 标签。
</div>。 - 文章链接起始标记:输入包裹单个文章链接的起始 HTML 标签,如果每个文章链接都在
<li class="item">里,这里就填<li class="item">。 - 文章链接结束标记:输入包裹单个文章链接的结束 HTML 标签。
</li>。 - 文章链接标签:输入包含文章链接的那个 HTML 标签名,通常是
a。 - 文章链接属性:输入文章链接所在的属性,通常是
href。
- 列表起始标记:输入包裹所有文章列表的起始 HTML 标签,如果所有文章都在
示例: 假设列表页 HTML 结构如下:
<ul class="article-list">
<li>
<a href="/news/123.html">文章标题 1</a>
<span>2025-10-27</span>
</li>
<li>
<a href="/news/124.html">文章标题 2</a>
<span>2025-10-26</span>
</li>
</ul>
那么你的列表规则应该配置为:
- 列表起始标记:
<ul class="article-list"> - 列表结束标记:
</ul> - 文章链接起始标记:
<li> - 文章链接结束标记:
</li> - 文章链接标签:
a - 文章链接属性:
href
配置好后,点击“测试”,如果能正确抓取到 /news/123.html 和 /news/124.html 等链接,说明列表页规则配置成功。
第 3 步:配置内容页规则
当列表页规则成功后,你需要告诉 DedeCMS 如何从抓取到的每一个文章链接(如 /news/123.html)中提取具体内容。

- 点击“选择内容页”,在弹出的窗口中填写一个典型的文章链接(
https://www.example.com/news/123.html),然后点击“浏览”。 - 页结构:
- 打开这个文章页面的源代码。
- 、作者、正文、图片等各自所在的 HTML 标签。
- 字段规则:页规则设置区域,你需要为每个要采集的字段(标题、内容等)分别配置规则。
- 采集字段列表:你可以在这里添加、删除、排序要采集的字段,默认有标题、内容等。
如何为每个字段配置规则(以“标题”为例):
-
字段名:选择你要配置的字段,如
title。 -
内容选择:
- 使用固定内容:如果这个字段是固定的,比如所有文章的来源都是“XX网”,就在这里填写。
- 抓取网页内容:如果这个字段需要从网页上提取,就选择此项,然后填写下面的规则。
-
内容起始标记:输入包含标题内容的起始 HTML 标签。
<h1 class="article-title">。 -
内容结束标记:输入包含标题内容的结束 HTML 标签。
</h1>。 -
内容过滤:非常重要! 这里可以写一些正则表达式来清理不需要的内容。
/<[^>]+>/:这个正则表达式可以移除所有 HTML 标签,只保留纯文本,对于标题通常不需要,但对于描述等字段很有用。/责任编辑:(.*)/:可以移除末尾的“责任编辑:XXX”这类文字。 字段的特殊处理:**
-
内容起始/结束标记:找到包含文章正文的
<div>或<p>标签,<div class="article-content">和</div>。 -
内容过滤:这里最常用正则表达式来清理广告、版权信息、无关链接等。
/<!--.*?-->/s:移除 HTML 注释。/<script.*?>.*?<\/script>/is:移除<script>标签及其内容。/<!--广告开始-->.*?<!--广告结束-->/is:移除特定标记的广告。/责任编辑:.*?/:移除责任编辑信息。
-
正文图片处理:
- 启用远程图片本地化:确保在第一步基本配置中开启了此选项。
- 图片本地化起始/结束标记:如果图片只在正文某一部分,可以在这里限定范围,如果整页都是正文,可以留空。
- 包含图片的标签:通常是
img。 - 图片地址属性:通常是
src。 - 图片替代文本属性:通常是
alt。
其他字段:
- 作者、来源、发布时间:方法类似,找到它们在页面中的 HTML 位置,填写起始和结束标记即可。
第 4 步:高级选项与测试
- 分页采集:如果文章内容有多页,可以在这里设置分页规则,
下一页按钮的链接规则。 - 过滤规则:可以设置一些关键词,如果文章标题或内容包含这些词,则不采集。
- 发布时间格式:如果抓取的是文本,需要告诉 DedeCMS 这个文本的日期格式,
%Y-%m-%d %H:%M:%S。
最后一步:测试
- 测试列表页:在列表页规则配置好后,点击“测试”,检查是否能正确抓取到文章链接。
- 页页规则配置好后,点击“测试”,检查是否能正确抓取到标题、正文等内容,并观察图片是否被正确替换。
完整实例演示
假设我们要采集一个网站的文章,其页面结构如下:
列表页 (list.html):
<div class="post-list">
<article class="item">
<h2><a href="/read/101.html">DedeCMS 采集教程详解</a></h2>
</article>
<article class="item">
<h2><a href="/read/102.html">PHP 开发最佳实践</a></h2>
</article>
</div>
页 (/read/101.html):**
<!DOCTYPE html>
<html>
<head>DedeCMS 采集教程详解 - XX技术博客</title>
</head>
<body>
<h1 class="main-title">DedeCMS 采集教程详解</h1>
<div class="info">作者:张三 | 来源:XX技术博客 | 发布时间:2025-10-27 10:00:00</div>
<div class="content">
<p>这是文章的第一段内容。</p>
<img src="https://www.example.com/images/pic1.jpg" alt="示例图片">
<p>这是文章的第二段内容。</p>
</div>
<div class="footer">版权所有 © 2025</div>
</body>
</html>
配置过程:
-
基本配置:
- 任务名称:XX技术博客采集
- 目标网址:
https://www.example.com/ - 列表页 URL:
https://www.example.com/list.html - 采集栏目:选择一个“技术文章”栏目
- 开启“下载远程图片”
-
列表页规则:
- 列表起始标记:
<div class="post-list"> - 列表结束标记:
</div> - 文章链接起始标记:
<article class="item"> - 文章链接结束标记:
</article> - 文章链接标签:
a - 文章链接属性:
href - 测试:应能抓取到
/read/101.html和/read/102.html。
- 列表起始标记:
-
内容页规则:
- 字段名:
title - 内容起始标记:
<h1 class="main-title"> - 内容结束标记:
</h1>
- 字段名:
- 字段名:
body - 内容起始标记:
<div class="content"> - 内容结束标记:
</div> - 内容过滤:
/<div class="footer">.*?<\/div>/is(移除页脚版权信息)
- 字段名:
- 作者:
- 字段名:
writer - 内容起始标记:
作者: - 内容结束标记:
- 字段名:
- 来源:
- 字段名:
source - 内容起始标记:
来源: - 内容结束标记:
- 字段名:
- 发布时间:
- 字段名:
pubdate - 内容起始标记:
发布时间: - 内容结束标记:
< - 日期格式:
%Y-%m-%d %H:%M:%S
- 字段名:
-
最终测试与采集:
- 保存所有规则。
- 回到采集任务列表,找到该任务,点击“开始采集”。
- 观察采集日志,看是否成功。
重要注意事项与技巧
- 尊重版权:采集他人内容时,务必遵守相关法律法规和网站的使用条款,建议注明来源和作者。
- 反爬虫机制:很多网站有反爬虫措施,可能会封禁你的 IP,可以设置采集间隔(如每次采集后等待几秒),或使用代理 IP。
- 网站结构变化:目标网站一旦改版,HTML 结构改变,你的采集规则就会失效,需要定期检查和更新规则。
- 正则表达式是关键:熟练掌握正则表达式能让你更精准地过滤和提取内容,是高级采集的必备技能。
- 从简单开始:如果采集失败,先从一个最简单的字段(如标题)开始测试,确保它能抓取到,再逐步添加和测试其他字段。
- DedeCMS 版本:不同版本的 DedeCMS 可能在界面上略有差异,但核心逻辑和规则配置方法基本一致。
希望这份详细的指南能帮助你掌握 DedeCMS 的采集功能!


